
open aiから公開されているwhisperについて、ある程度の精度を保ったままもっと早くしたい人向けにちょうどよさそうです。
通常のwhisperと同じくsrtで出力してくれるなら実用的ですので、やってみます。
準備
pythonのインストール
pythonのインストールについてはこちらをご確認ください。
conda環境を作りたいのでminiconda3でPythonをインストールしています。
Pathを通すという項目にチェックが付いていないので、後から個別に作業するのは面倒なためこれもチェックを入れてインストールします。
Conda 環境の準備
conda create -n faster-whisper
conda activate faster-whisperfaster whisperの準備
pip install faster-whispermodelファイルをct2で使えるように変換
ct2-transformers-converterでコマンドを打つとオプションが表示されるのでそれに従って以下のようにopenaiのWhisperのlarge-v2モデルを変換します。
ct2-transformers-converter --model openai/whisper-large-v2 --output_dir whisper-large-v2-ct2 --copy_files tokenizer.json --quantization float16whisper-large-v2-ct2フォルダができて、この中にlarge-v2のモデルが格納されてfaster-whisperで使います。
Nvidia cudnnをインストール
Nvidia のCuda Toolkit 11.8 と cudnn v8をインストールします。
新しいバージョンにしていないのは、この組み合わせでないと動作しないとあったので動作する少し古いバージョンにしています。
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8にCUDAはインストールされると思いますので、cudnnのファイルはv11.8フォルダの中の同じフォルダ名のところに上書きでインストールしました。
- includeフォルダ
- binフォルダ
- libフォルダ
Zlibwapi.dllをインストールする必要があり、これをインストールしないとcudnnがすべて認識されませんので、binフォルダに一緒に格納します。
システム環境変数を選定します。
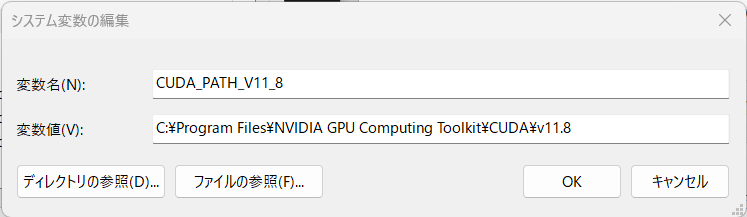
オーディオファイルの準備
オーディオファイルの準備方法についてはこちらをご確認ください。
faster whisperの実行ファイルを作る
faster whisperの実行環境が整ったのであとは、Python実行ファイルを作成します。
sys_argを設定して、batファイルにオーディオファイルをD&Dするとpythonファイルでオーディオファイルを受け取るような流れにします。

コメント